Mistral 7B and BAAI on Workers AI vs. OpenAI Models for RAG
Which models for your AI-powered applications

In the rapidly progressing world of artificial intelligence, choosing the right model for AI-powered applications is crucial. This article explores a comparative analysis of the Mistral 7B model, a promising alternative to OpenAI’s GPT models and BAAI models in the context of Retrieval Augmented Generation (RAG) applications. But first, let’s understand the landscape.
Understanding RAG Pipelines
RAG pipelines enhance the capabilities of Large Language Models (LLMs) by providing them with external ‘research’ to inform their responses. Let me explain.
Imagine you are a pastry chef, and someone asks you how to make a good chocolate cake. That’s an easy one for you since you have made countless chocolate cakes in the past. But what if someone asks you about making Tandoori chicken? You probably do not have the recipe on the top of your head, but with a little bit of research, you will likely be able to answer that question. The same applies to LLMs.
When the user asks the LLM a question, the RAG pipeline does the search to provide more context and helps steer the model towards a more accurate and helpful answer. Typically, the context is a piece of information stored in a document or a database that the model hasn’t seen during training.
The below diagram illustrates the RAG process using Neon Docs Chatbot as an example. The diagram shows three main steps:
- Embedding generation: we need an embedding model to turn the user’s query into a query vector.
- Context retrieval: This is the process of looking for the information in a document or a database using similarity search.
- Completion (or text) generation: In this step, the application provides the completion model with the user query and the context to generate an answer.

We now want to explore open-source alternatives for text generation and embedding models. But first, let’s explain why open-source models are becoming increasingly popular.
What are open-source AI models, and why should you care?
The short answer is transparency.
OpenAI provides developers with GPT and ADA models that are essential for RAG pipelines. However, those models operate as black boxes, which can pose a security concern for some, accelerating the interest in open-source models such as Llama2 and Mistral 7B.
Being open-source in the AI model context means a transparent training process and output.
Mistral AI, for instance, opened the code and weights of its 7-billion-parameter open-source large language model (LLM) Mistral 7B to the public and explained how the model uses a sliding window to speed up inference and reduce memory pressure, which gives the model an edge over other open-source models.
Let’s explore the Mistral 7B model in more detail.
Introducing Mistral 7B: A New Contender
The Mistral 7B model is an alternative to OpenAI’s GPT models, engineered for performance and efficiency. According to a recent paper, Mistral 7B outperforms existing models like Llama 2 (13B parameters) across all evaluated benchmarks, showcasing superior performance in areas such as reasoning, mathematics, and code generation.
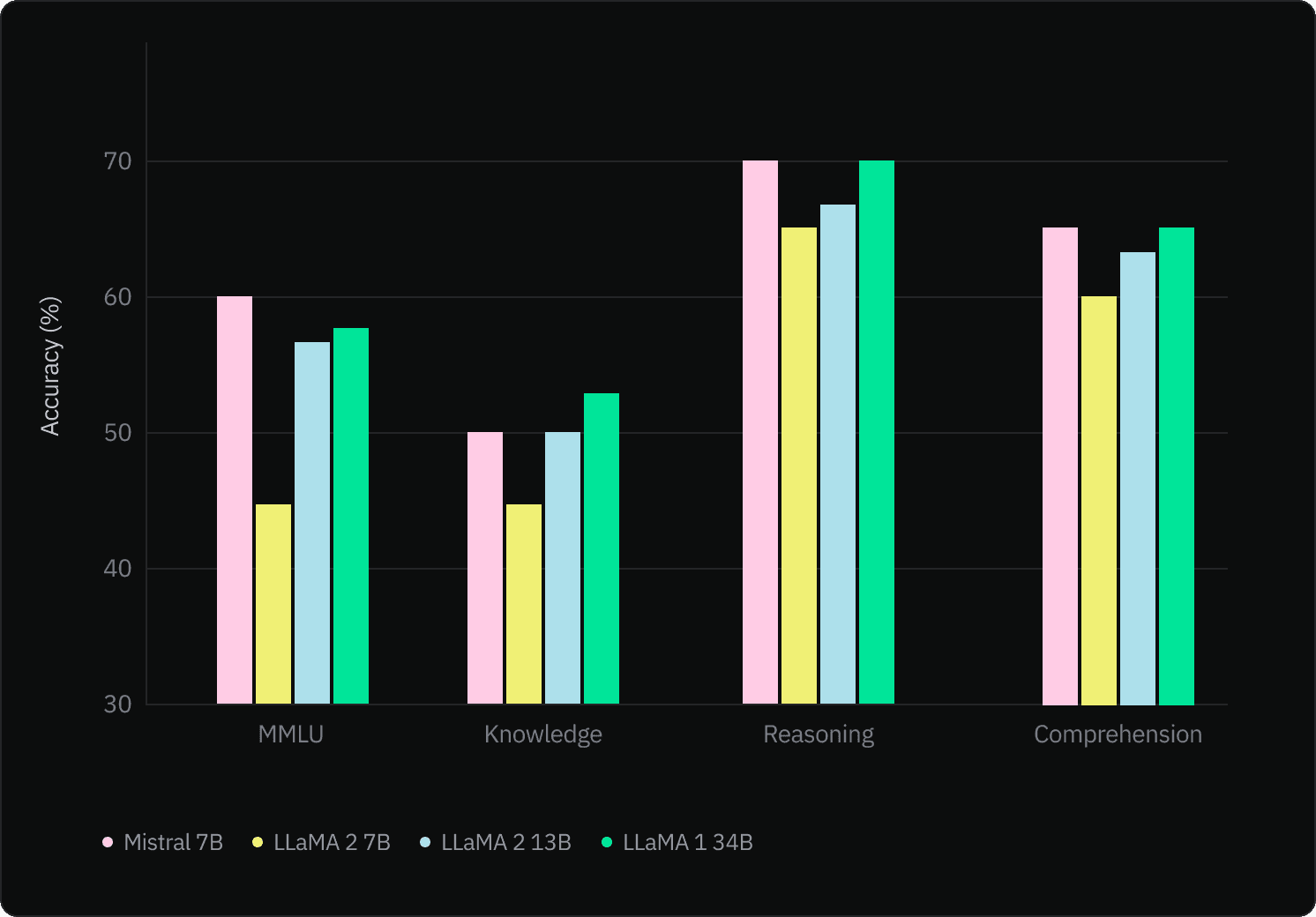
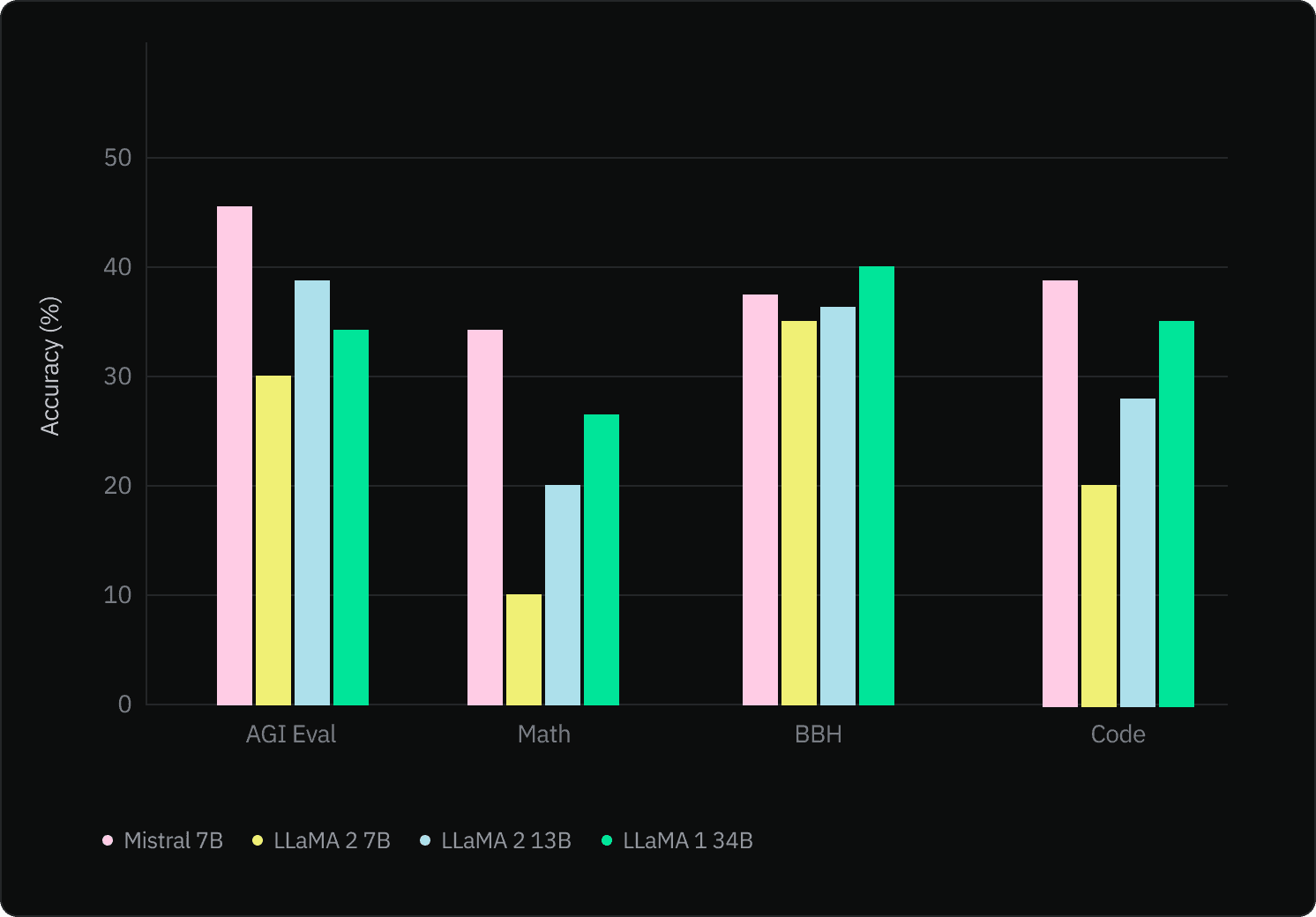
Mistral 7B has been released under the Apache 2.0 license, with a reference implementation available for easy deployment on cloud platforms like AWS, GCP, and Azure or locally.
The paper’s claims are impressive, so I wanted to experience firsthand how good the LLM is.
BGE: The open-source Embedding generation model
BGE embedding is a general Embedding Model pre-trained using retromae that can fine-tuned. Interestingly, BGE comes in three dimension sizes:
- small: 384 dimensions
- base: 768 dimensions
- large: 1024 dimensions
This means that you can reduce the size of storage related to your embeddings by 30-80%, depending on the BGE model you choose.
I used the base-768 model on Cloudflare Workers AI for Text Embedding generation for this article.
Methodology of Comparative Analysis
For a hands-on evaluation, I replaced gpt-3.5-turbo with mistral-7b-instruct-v0.1 and text-embedding-ada-002 with BAAI’s bge-base-en-v1.5 in a Neon Docs chatbot. I then compared their responses to eight PostgreSQL-related questions.
Technical Setup
- Text generation model: Mistral 7B on Cloudflare Workers AI.
- Embedding model: BGE base-768 on Cloudflare Workers AI.
- Experiment models: mistral-7b-instruct-v0.1, gpt-3.5-turbo, text-embedding-ada-002, bge-base-en-v1.5.
Cloudflare Workers AI allows you to run text, image, and embedding generation models using serverless GPUs. Note that Workers AI is currently in Open Beta and is not recommended for production data.

I tested Mistral 7B on a virtual machine with 24GB of vRAM and NVIDIA GPUs for $1.3 per hour. But our friends at Cloudflare released Workers AI, a GPU-powered serverless environment to run machine learning models that better fit my use case.
For those interested in deploying their own Mistral 7B instance, I added instructions at the end of this article to deploy using the HuggingFace inference endpoint.
In this analysis, we used the mistralai/Mistral-7B-Instruct-v0.1 model, which has been fine-tuned for conversation and answering questions.
The default max number of tokens per query is 1512. For this test, I had to increase the max input length and number of tokens to 3000. Note that the larger this value, the more memory each request will consume.
Results and Discussion
Context quality
In the RAG pipeline, the context is the concatenation of texts resulting from a semantic search.
Therefore, the quality of our context is heavily correlated to the quality of the semantic search using bge-base-en-v1.5 and text-embedding-ada-002 embeddings models. So, the question is: how different would my context be if I switched the text embedding model?
Our analysis showed that the bge-base-en-v1.5 and text-embedding-ada-002 models provided similar results 46% of the time. A deeper dive using Jaccard and Cosine similarity scores indicated a significant overlap in contexts, suggesting comparable quality.
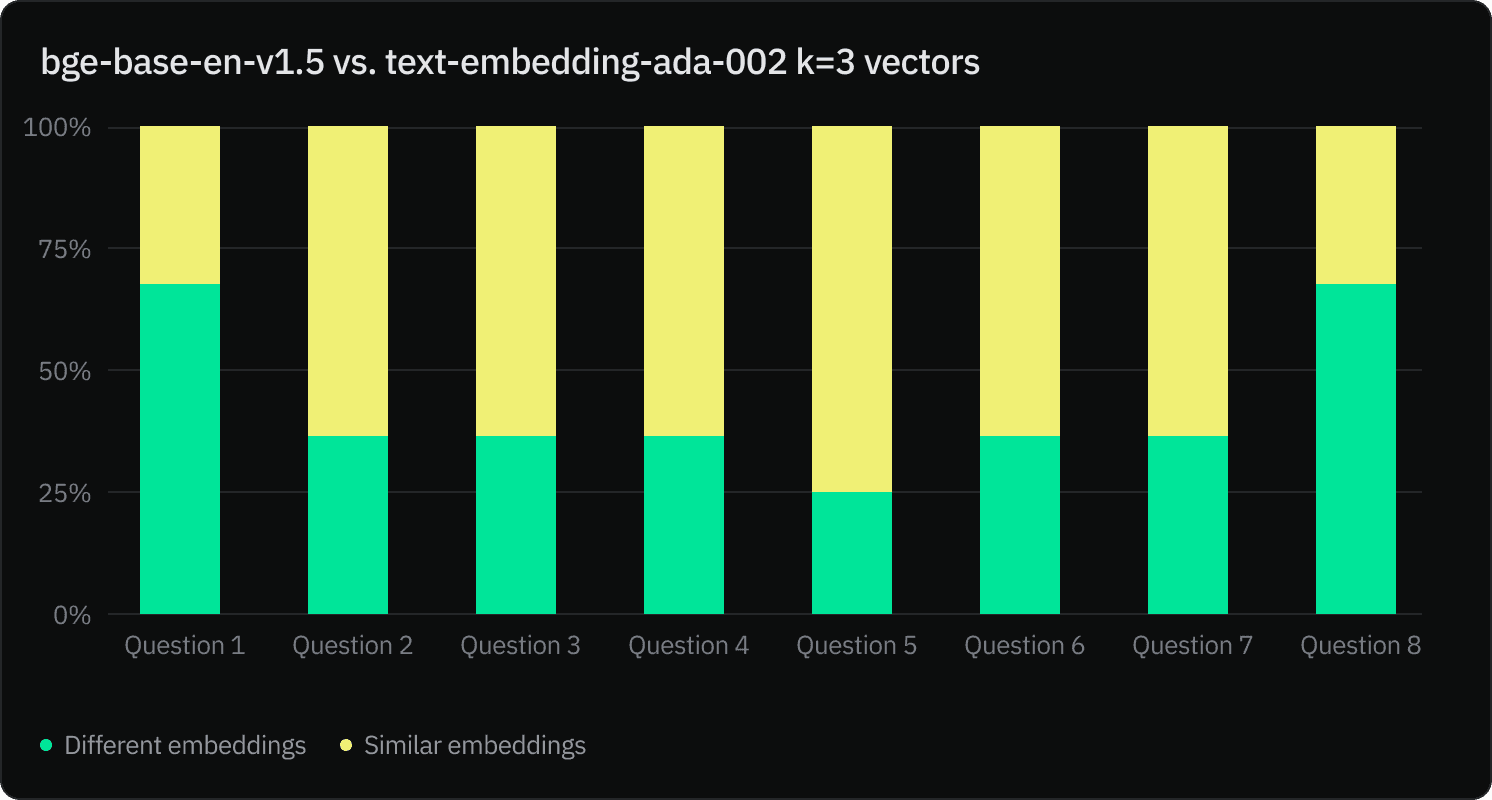
With the number of returned chunks k=3, the bge-base-en-v1.5 and text-embedding-ada-002 models return similar results only 46% of the time. This number is reduced to 42% with k=10.
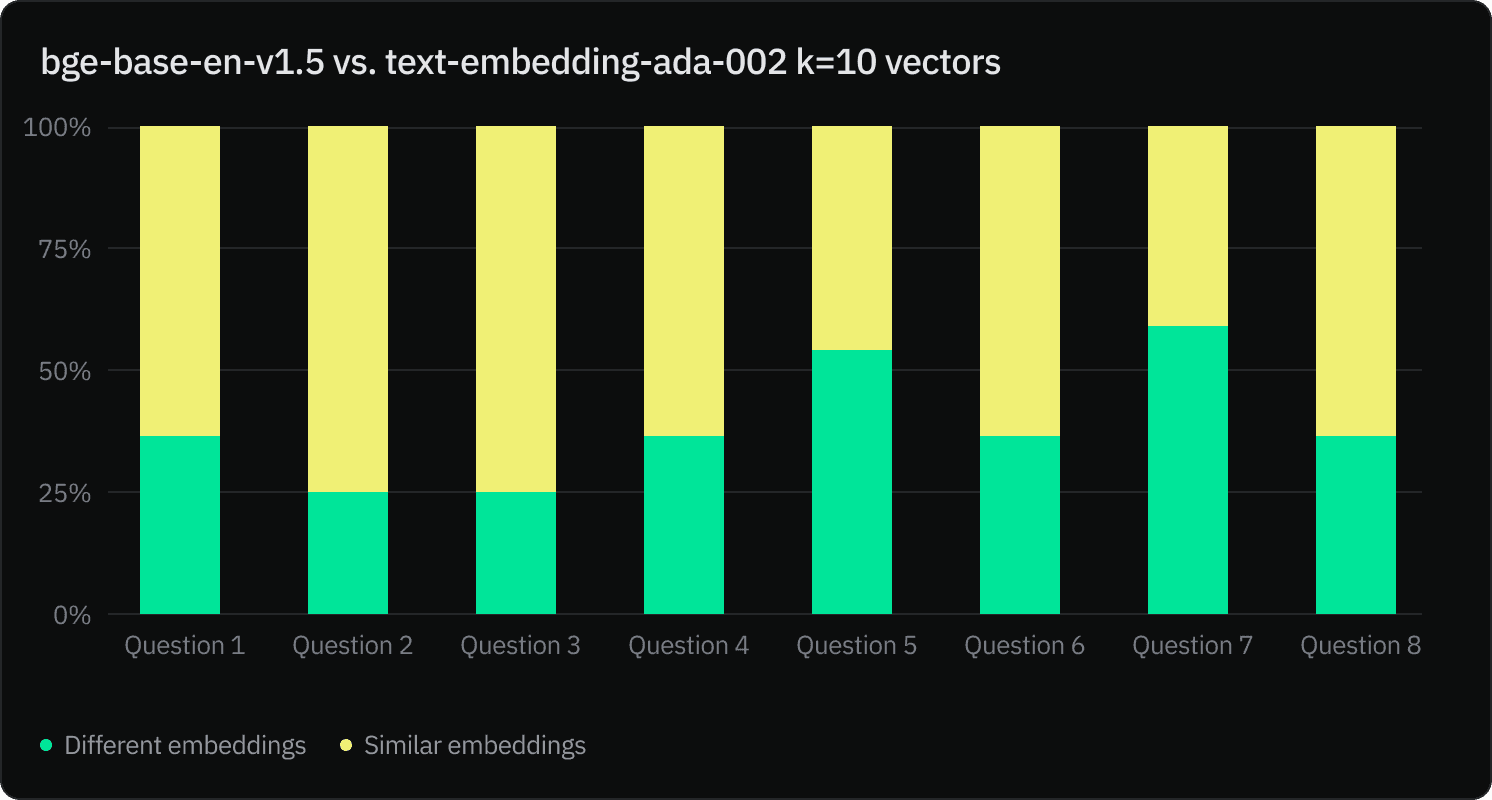
Further analysis using Jaccard and Cosine similarity scores to determine intersecting words and count shows that half of the contexts generated by the two models are similar and often share words.
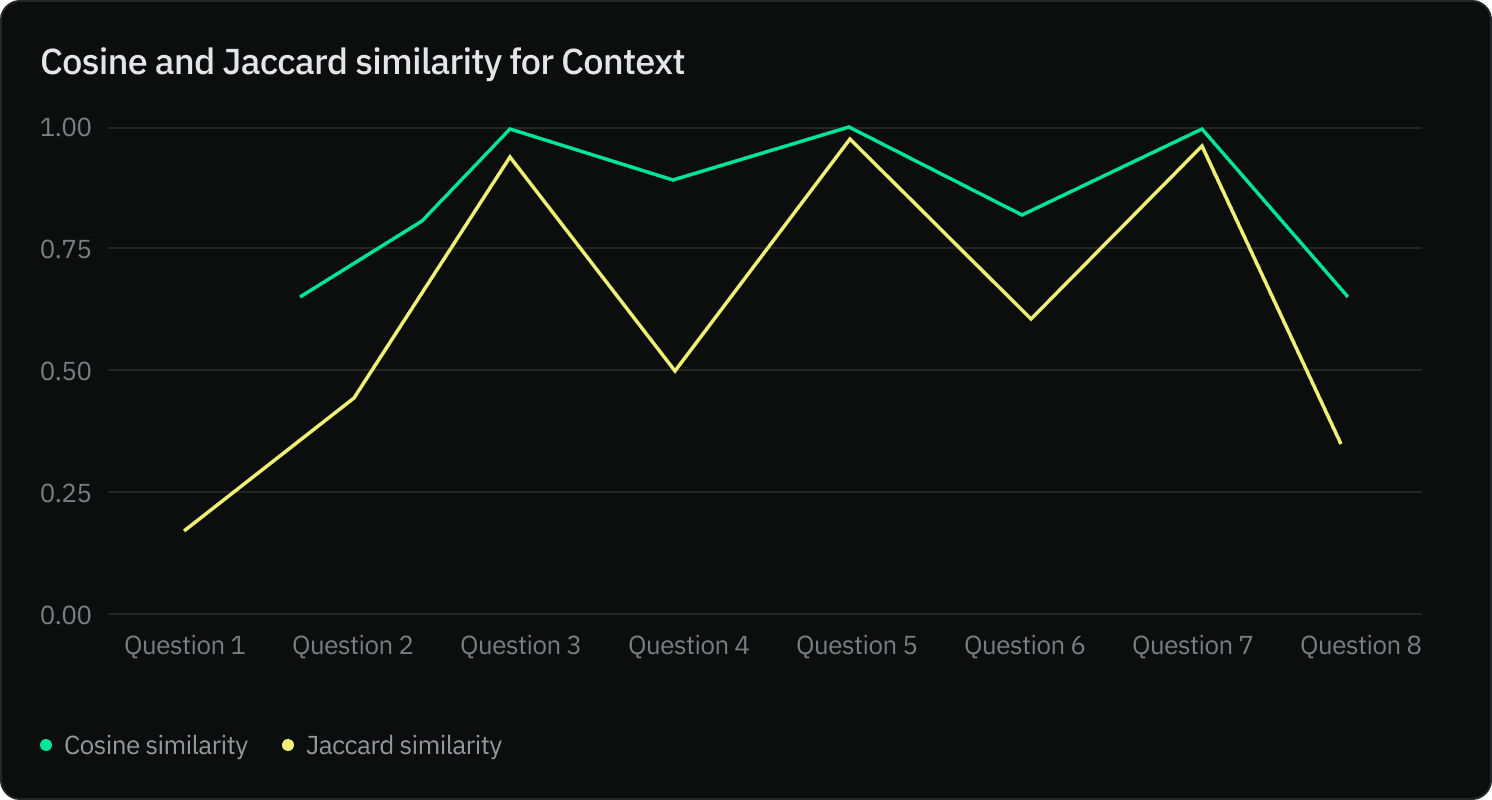
Note: In the above, we extracted the word’s frequency count in the context using TF-IDF to calculate the cosine similarity score. Typically, cosine similarity is sensitive to the frequency of words, while Jaccard similarity purely focuses on the intersecting words.
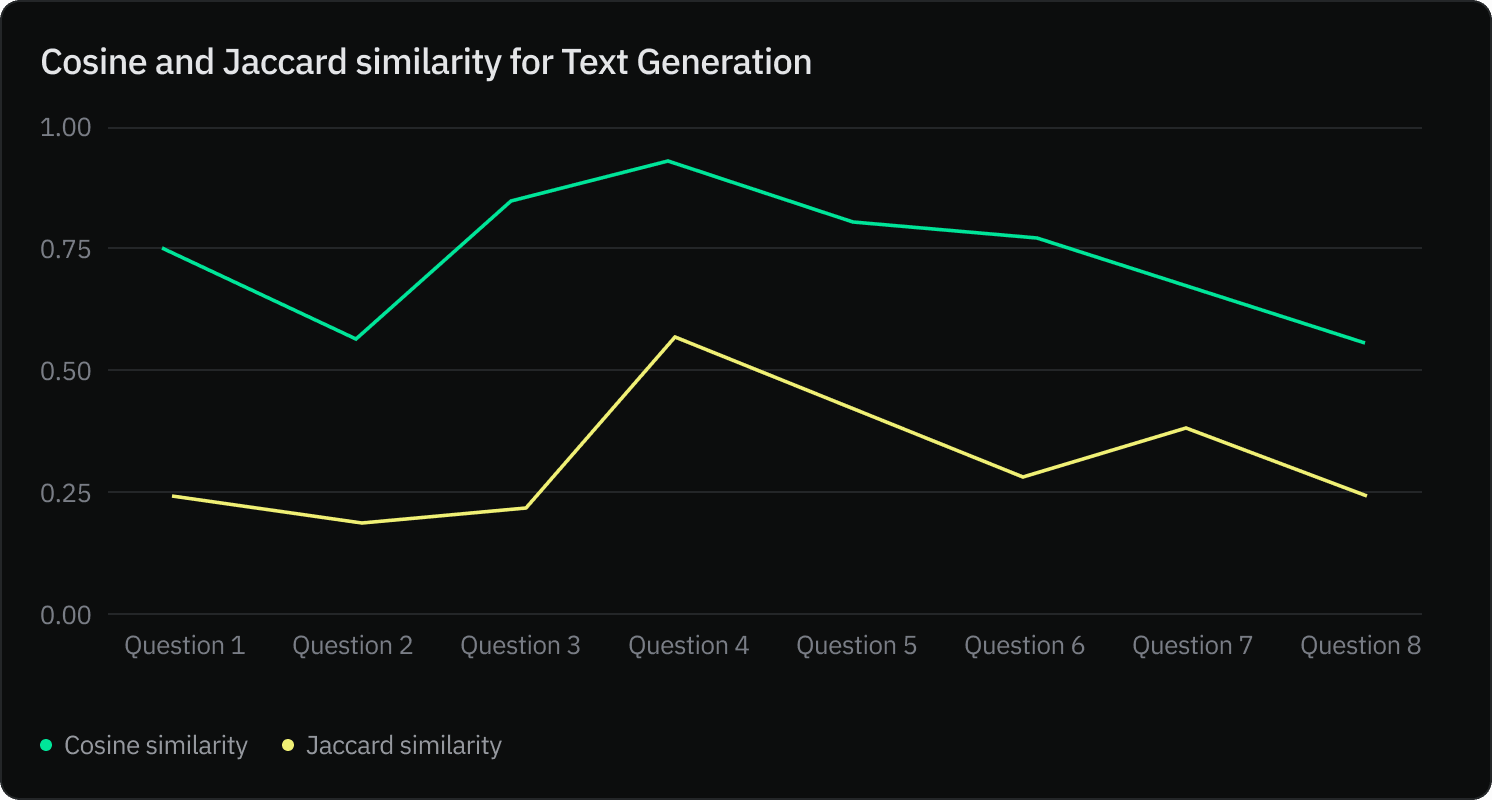
More analysis of the completions generated by gpt-3.5-turbo model shows strong cosine similarity among texts. Competitions share an average of 40% of words.
Even for questions 3, 5, and 7, where retrieved contexts using text-embedding-ada-002 and bge-base-en-v1.5 embedding models were quite similar; the generated texts were different. This change is probably due to the LLM temperature set to default (0.7), which controls the degree of randomness in the response and allows for variations in the generated text.
Text generation quality
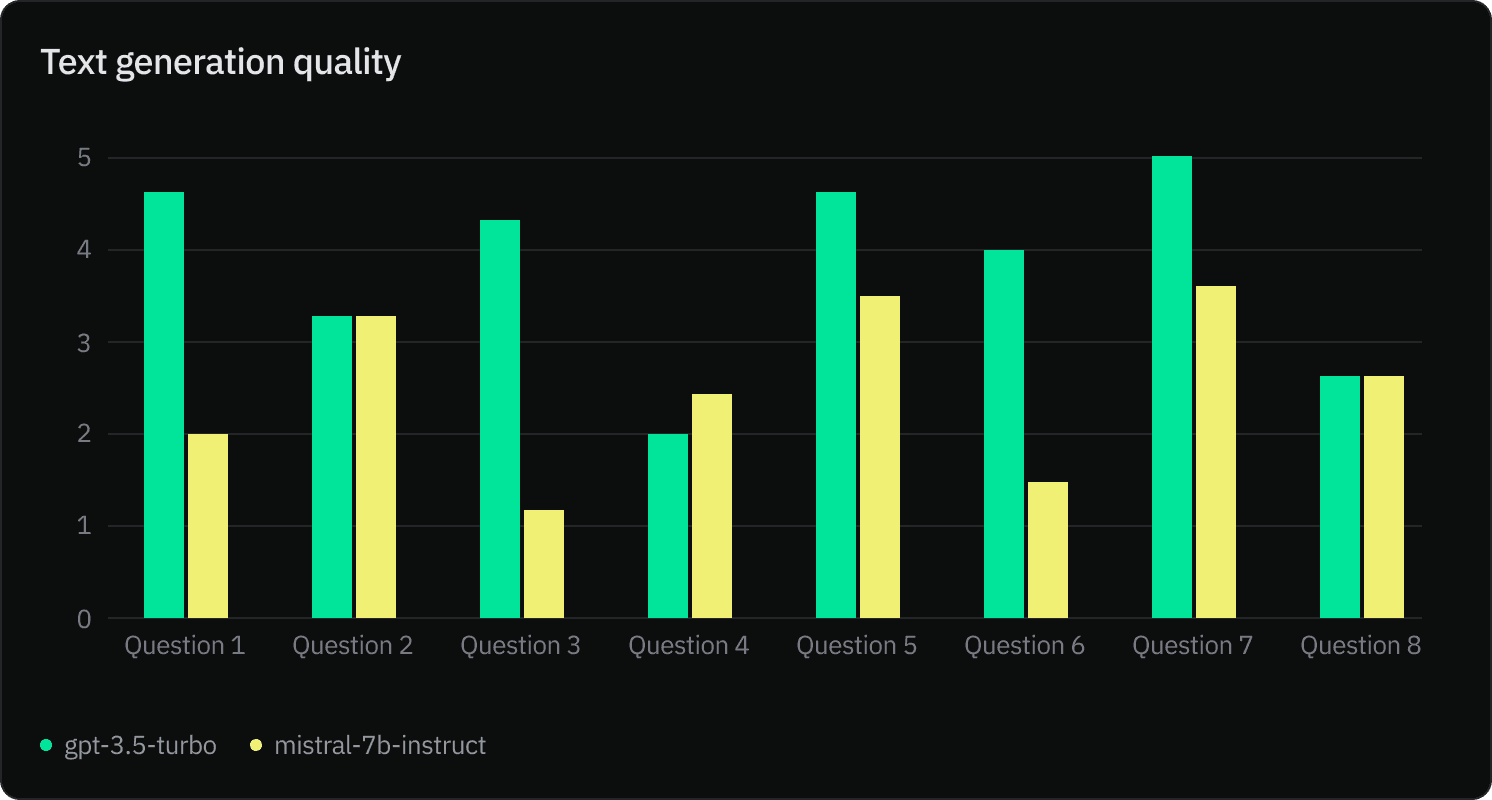
Quality is subjective. Therefore, we surveyed Postgres and Neon experts to rate the generated text quality. gpt-3.5-turbo scored an average of 3.8/5, outperforming mistral-7b-instruct-v0.1‘s 2.5/5. (1 being very bad and 5 being very good).
The answers shared in the survey were generated using context retrieved with text-embedding-ada-002 embedding model. The ground truth in this experiment is the Postgres and Neon documentation.
Conclusion
The BGE model, with its varying dimension sizes, allows for a customizable approach to managing storage and computational resources since smaller vector sizes reduce storage and semantic search query execution time.
Our analysis revealed that the bge-base-en-v1.5 and text-embedding-ada-002 models, while similar in results to some extent, display unique characteristics in their context generation capabilities. The observed differences in the semantic search results – with a 46% similarity rate in some instances – underscore the importance of choosing the right embedding model based on the specific requirements of an application.
In the case of our chatbot, these initial results suggest that the output quality wouldn’t change drastically by migrating to bge-base-en-v1.5. Migrating text generation models, on the other hand, is a different story.
The Mistral 7B model stands out as a strong contender. Its ability to outperform models like Llama 2 in reasoning, mathematics, and code generation, coupled with its ease of deployment, makes it a viable option for those seeking an alternative to OpenAI’s GPT models.
However, the difference in performance in our tests – with gpt-3.5-turbo outperforming mistral-7b-instruct-v0.1 – suggests that while newer models like Mistral 7B are closing the gap, there remains room for improvement and innovation.
Zephyr-7B-beta, a fine-tuned version of mistralai/Mistral-7B-v0.1 that was trained on a mix of publicly available and synthetic datasets, looks promising and could further reduce the gap.
What about you? Which models do you use for your RAG pipelines? Join us on Discord and tell us about your experience with AI models and what you think.
Note: A special thanks to Stan Girard for inspiring the topic of this article. His suggestion and enthusiasm for AI have been invaluable in shaping this discussion.
BONUS: Deploy Mistral 7B Instruct on HuggingFace
For the ones interested in deploying on Huggingface:
Pre-requisites:
– HuggingFace account
– HuggingFace Token
1. On HuggingFace, locate the “Deploy” drop-down and click on “Inference Endpoints”

2. Select the default instance with 24GB of vRAM and an NVIDIA GPU, then click on “Create Endpoint” at the bottom of the page.

3. Once your instance is deployed, you can test your endpoint on HuggingFace:
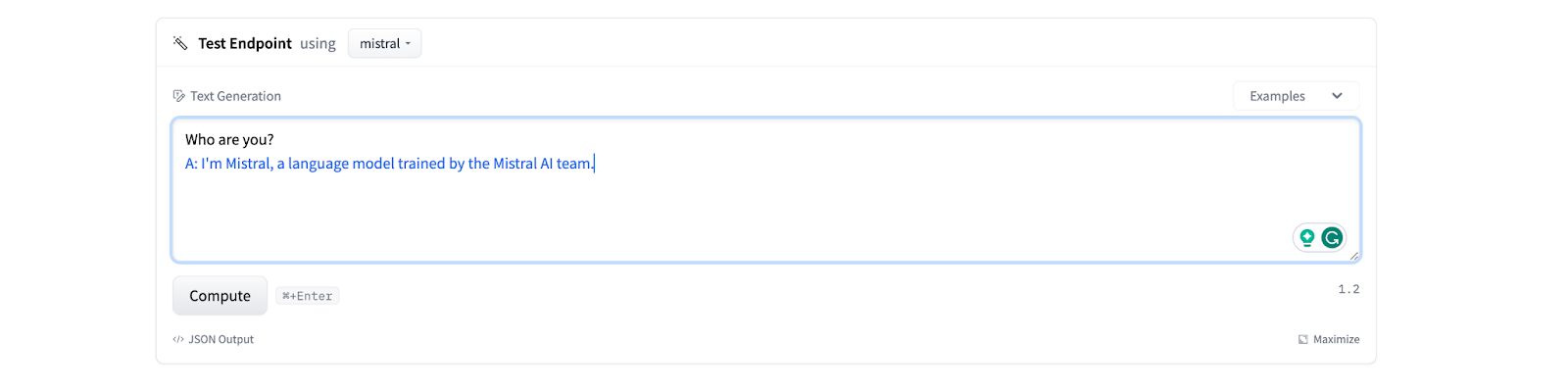
Or in code:
import requests
API_URL = "https://asdfghjklrtyui.us-east-1.aws.endpoints.huggingface.cloud"
headers = {
"Authorization": "Bearer XXXXXX",
"Content-Type": "application/json"
}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "Who are you?",
})
# A: I'm Mistral, a language model trained by the Mistral AI team.


